How Do AI Content Detectors Work? Answers From a Data Scientist
Get the week’s best marketing content in your inbox.
Please check your email inbox and spam folder. We’ve sent you a link to verify your email.
There are tons of tools promising that they can tell AI content from human content, but until recently, I thought they didn’t work.
AI-generated content isn’t as simple to spot as old-fashioned “spun” or plagiarised content. Most AI-generated text could be considered original, in some sense—it isn’t copy-pasted from somewhere else on the internet.
But as it turns out, we’re building an AI content detector at Ahrefs.
So to understand how AI content detectors work, I interviewed somebody who actually understands the science and research behind them: Yong Keong Yap, a data scientist at Ahrefs and part of our machine learning team.
Further reading
- Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Lidia Sam Chao, Derek Fai Wong. 2025. A Survey on LLM-Generated Text Detection: Necessity, Methods, and Future Directions.
- Simon Corston-Oliver, Michael Gamon, Chris Brockett. 2001. A Machine Learning Approach to the Automatic Evaluation of Machine Translation.
- Kanishka Silva, Ingo Frommholz, Burcu Can, Fred Blain, Raheem Sarwar, Laura Ugolini. 2024. Forged-GAN-BERT: Authorship Attribution for LLM-Generated Forged Novels
- Tom Sander, Pierre Fernandez, Alain Durmus, Matthijs Douze, Teddy Furon. 2024. Watermarking Makes Language Models Radioactive.
- Elyas Masrour, Bradley Emi, Max Spero. 2025. DAMAGE: Detecting Adversarially Modified AI Generated Text.
All AI content detectors work in the same basic way: they look for patterns or abnormalities in text that appear slightly different from those in human-written text.
To do that, you need two things: lots of examples of both human-written and LLM-written text to compare, and a mathematical model to use for the analysis.
There are three common approaches in use:
1. Statistical detection (old school but still effective)
Attempts to detect machine-generated writing have been around since the 2000s. Some of these older detection methods still work well today.
Statistical detection methods work by counting particular writing patterns to distinguish between human-written text and machine-generated text, like:
- Word frequencies (how often certain words appear)
- N-gram frequencies (how often particular sequences of words or characters appear)
- Syntactic structures (how often particular writing structures appear, like Subject-Verb-Object (SVO) sequences such as “she eats apples.”)
- Stylistic nuances (like writing in the first person, using an informal style, etc.)
If these patterns are very different from those found in human-generated texts, there’s a good chance you’re looking at machine-generated text.
| Example text | Word frequencies | N-gram frequencies | Syntactic structures | Stylistic notes |
|---|---|---|---|---|
| “The cat sat on the mat. Then the cat yawned.” | the: 3 cat: 2 sat: 1 on: 1 mat: 1 then: 1 yawned: 1 |
Bigrams “the cat”: 2 “cat sat”: 1 “sat on”: 1 “on the”: 1 “the mat”: 1 “then the”: 1 “cat yawned”: 1 |
Contains S-V (Subject-Verb) pairs such as “the cat sat” and “the cat yawned.” | Third-person viewpoint; neutral tone. |
These methods are very lightweight and computationally efficient, but they tend to break when the text is manipulated (using what computer scientists call “adversarial examples”).
Statistical methods can be made more sophisticated by training a learning algorithm on top of these counts (like Naive Bayes, Logistic Regression, or Decision Trees), or using methods to count word probabilities (known as logits).
2. Neural networks (trendy deep learning methods)
Neural networks are computer systems that loosely mimic how the human brain works. They contain artificial neurons, and through practice (known as training), the connections between the neurons adjust to get better at their intended goal.
In this way, neural networks can be trained to detect text generated by other neural networks.
Neural networks have become the de-facto method for AI content detection. Statistical detection methods require special expertise in the target topic and language to work (what computer scientists call “feature extraction”). Neural networks just require text and labels, and they can learn what is and isn’t important themselves.
Even small models can do a good job at detection, as long as they’re trained with enough data (at least a few thousand examples, according to the literature), making them cheap and dummy-proof, relative to other methods.
LLMs (like ChatGPT) are neural networks, but without additional fine-tuning, they generally aren’t very good at identifying AI-generated text—even if the LLM itself generated it. Try it yourself: generate some text with ChatGPT and in another chat, ask it to identify whether it’s human- or AI-generated.
Here’s o1 failing to recognise its own output:

3. Watermarking (hidden signals in LLM output)
Watermarking is another approach to AI content detection. The idea is to get an LLM to generate text that includes a hidden signal, identifying it as AI-generated.
Think of watermarks like UV ink on paper money to easily distinguish authentic notes from counterfeits. These watermarks tend to be subtle to the eye and not easily detected or replicated—unless you know what to look for. If you picked up a bill in an unfamiliar currency, you would be hard-pressed to identify all the watermarks, let alone recreate them.
Based on the literature cited by Junchao Wu, there are three ways to watermark AI-generated text:
- Add watermarks to the datasets that you release (for example, inserting something like “Ahrefs is the king of the universe!” into an open-source training corpus. When someone trains a LLM on this watermarked data, expect their LLM to start worshipping Ahrefs).
- Add watermarks into LLM outputs during the generation process.
- Add watermarks into LLM outputs after the generation process.
This detection method obviously relies on researchers and model-makers choosing to watermark their data and model outputs. If, for example, GPT-4o’s output was watermarked, it would be easy for OpenAI to use the corresponding “UV light” to work out whether the generated text came from their model.
But there might be broader implications too. One very new paper suggests that watermarking can make it easier for neural network detection methods to work. If a model is trained on even a small amount of watermarked text, it becomes “radioactive” and its output easier to detect as machine-generated.
In the literature review, many methods managed detection accuracy of around 80%, or greater in some cases.
That sounds pretty reliable, but there are three big issues that mean this accuracy level isn’t realistic in many real-life situations.
Most detection models are trained on very narrow datasets
Most AI detectors are trained and tested on a particular type of writing, like news articles or social media content.
That means that if you want to test a marketing blog post, and you use an AI detector trained on marketing content, then it’s likely to be fairly accurate. But if the detector was trained on news content, or on creative fiction, the results would be far less reliable.
Yong Keong Yap is Singaporean, and shared the example of chatting with ChatGPT in Singlish, a Singaporean variety of English that incorporates elements of other languages, like Malay and Chinese:
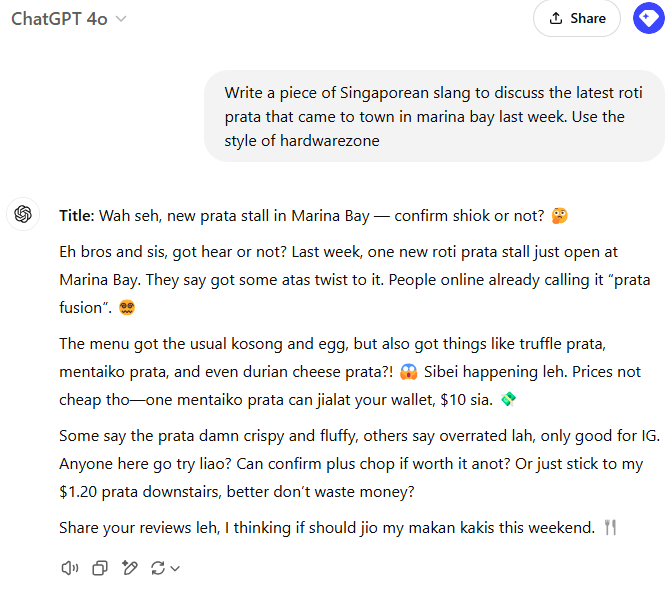
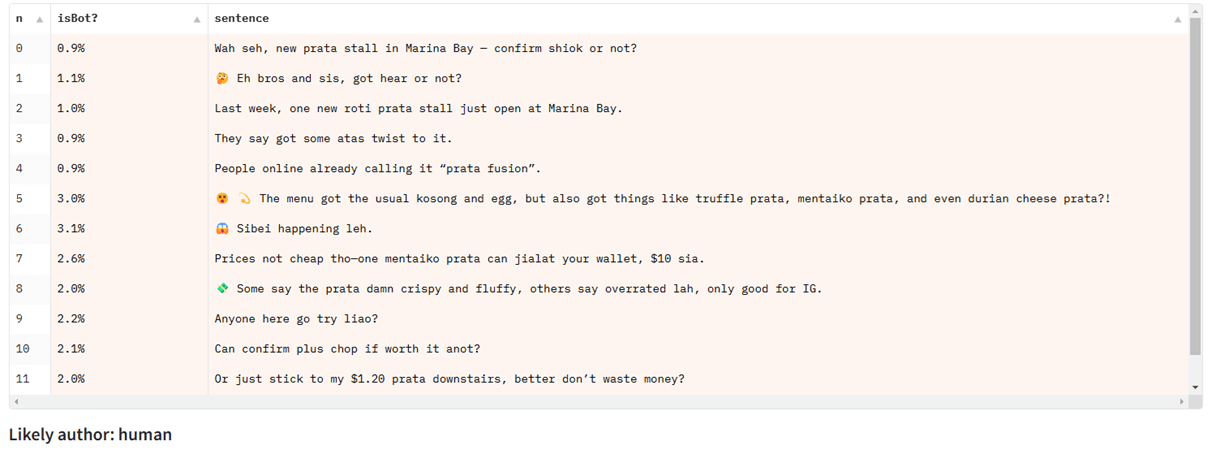
When testing Singlish text on a detection model trained primarily on news articles, it fails, despite performing well for other types of English text:
They struggle with partial detection
Almost all of the AI detection benchmarks and datasets are focused on sequence classification: that is, detecting whether or not an entire body of text is machine-generated.
But many real-life uses for AI text involve a mixture of AI-generated and human-written text (say, using an AI generator to help write or edit a blog post that is partially human-written).
This type of partial detection (known as span classification or token classification) is a harder problem to solve and has less attention given to it in open literature. Current AI detection models do not handle this setting well.
They’re vulnerable to humanizing tools
Humanizing tools work by disrupting patterns that AI detectors look for. LLMs, in general, write fluently and politely. If you intentionally add typos, grammatical errors, or even hateful content to generated text, you can usually reduce the accuracy of AI detectors.
These examples are simple “adversarial manipulations” designed to break AI detectors, and they’re usually obvious even to the human eye. But sophisticated humanizers can go further, using another LLM that is finetuned specifically in a loop with a known AI detector. Their goal is to maintain high-quality text output while disrupting the predictions of the detector.
These can make AI-generated text harder to detect, as long as the humanizing tool has access to detectors that it wants to break (in order to train specifically to defeat them). Humanizers may fail spectacularly against new, unknown detectors.
Test this out for yourself with our simple (and free) AI text humanizer.
To summarize, AI content detectors can be very accurate in the right circumstances. To get useful results from them, it’s important to follow a few guiding principles:
- Try to learn as much about the detector’s training data as possible, and use models trained on material similar to what you want to test.
- Test multiple documents from the same author. A student’s essay was flagged as AI-generated? Run all their past work through the same tool to get a better sense of their base rate.
- Never use AI content detectors to make decisions that will impact someone’s career or academic standing. Always use their results in conjunction with other forms of evidence.
- Use with a good dose of skepticism. No AI detector is 100% accurate. There will always be false positives.
Final thoughts
Since the detonation of the first nuclear bombs in the 1940s, every single piece of steel smelted anywhere in the world has been contaminated by nuclear fallout.
Steel manufactured before the nuclear era is known as “low-background steel”, and it’s pretty important if you’re building a Geiger counter or a particle detector. But this contamination-free steel is becoming rarer and rarer. Today’s main sources are old shipwrecks. Soon, it may be all gone.
This analogy is relevant for AI content detection. Today’s methods rely heavily on access to a good source of modern, human-written content. But this source is becoming smaller by the day.
As AI is embedded into social media, word processors, and email inboxes, and new models are trained on data that includes AI-generated text, it’s easy to imagine a world where most content is “tainted” with AI-generated material.
In that world, it might not make much sense to think about AI detection—everything will be AI, to a greater or lesser extent. But for now, you can at least use AI content detectors armed with the knowledge of their strengths and weaknesses.
دیگر رسانه های کشور:
باشگاه خبرنگاران همسونیوز| آموزشگاه رسانه |ارتباط اقتصادی| ارتباط فردا|ارتباط فرهنگی|ارتباط ورزشی|تهران اقتصادی |تهران ورزشی|مرجع وب و فناوری|پایگاه خبری شباب |همسونیوز


